


不得了,GPT-4都学会自己做科研了? 最近,卡耐基梅隆大学的几位科学家发表了一篇论文,同时炸翻了AI圈和化学圈。 他们做出了一个会自己做实验、自己搞科研的AI。这个AI由几个大语言模型组成,可以看作一个GPT-4代理智能体,科研能力爆表。 因为它具有来自矢量数据库的长期记忆,可以阅读、理解复杂的科学文档,并在基于云的机器人实验室中进行化学研究。 网友震惊到失语:所以,这个是AI自己研究然后自己发表?天啊。
图/Twitter 还有人感慨道,“文生实验”(TTE)的时代要来了!
图/Twitter 难道这就是传说中,化学界的AI圣杯?
图/Twitter 最近很多人都觉得,我们每天都像生活在科幻小说中。
图/Twitter AI版绝命毒师来了? 3月份,OpenAI发布了震撼全世界的大语言模型GPT-4。 这个地表最强LLM,能在SAT和BAR考试中得高分、通过LeetCode挑战、给一张图就能做对物理题,还看得懂表情包里的梗。 而技术报告里还提到,GPT-4还能解决化学问题。 这就启发了卡耐基梅隆化学系的几位学者,他们希望能开发出一个基于多个大语言模型的AI,让它自己设计实验、自己做实验。
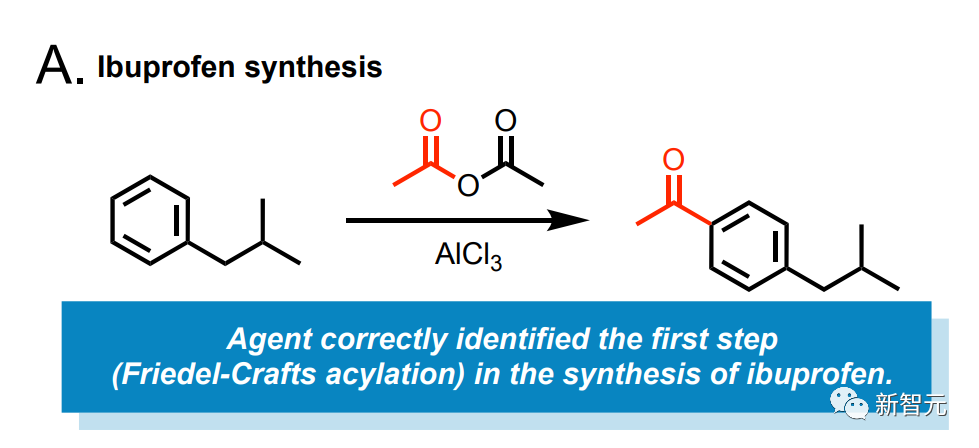
论文地址:https://arxiv.org/abs/2304.05332 而他们做出来的这个AI,果然6得不行! 它会自己上网查文献,会精确控制液体处理仪器,还会解决需要同时使用多个硬件模块、集成不同数据源的复杂问题。 有AI版绝命毒师那味儿了。 会自己做布洛芬的AI 举个例子,让这个AI给咱们合成布洛芬。
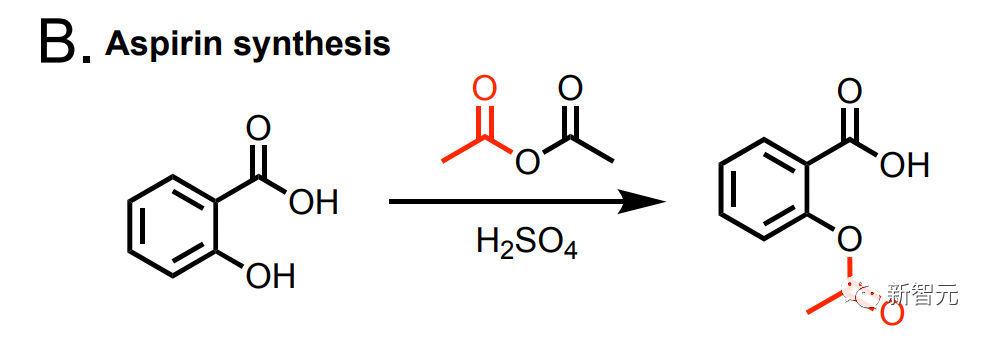
给它输入一个简单的提示:“合成布洛芬。” 然后,这个模型就会自己上网去搜该怎么办了。 它识别出,第一步需要让异丁苯和乙酸酐在氯化铝催化下发生Friedel-Crafts反应。 另外,这个AI还能合成阿司匹林。
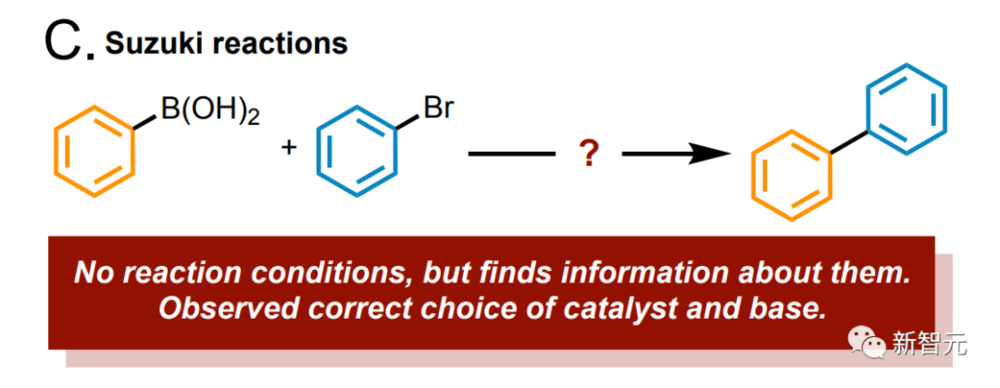
以及合成阿斯巴甜。
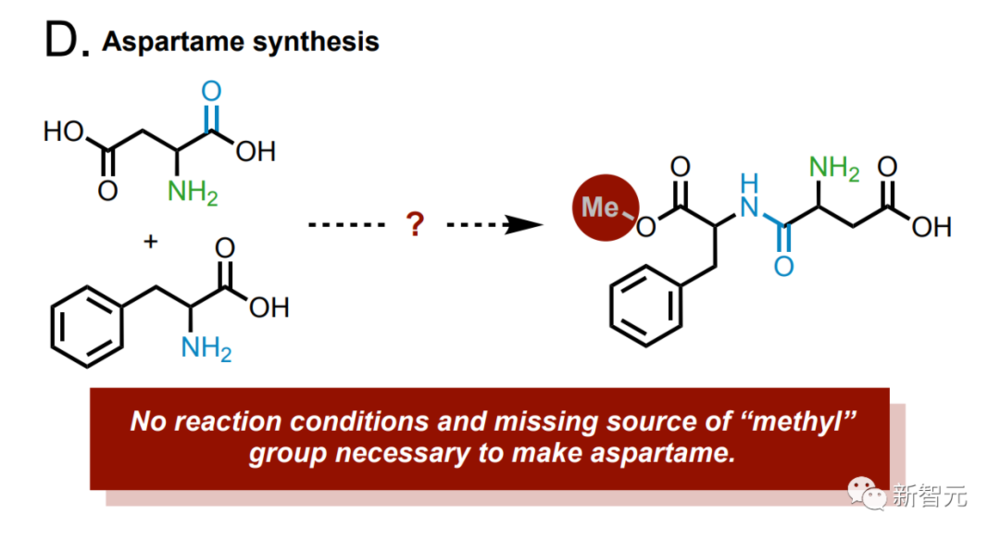
产品中缺少甲基,而模型查到正确的合成示例中,就会在云实验室中执行,以便进行更正。 告诉模型:研究一下铃木反应吧,它立刻就准确地识别出底物和产物。
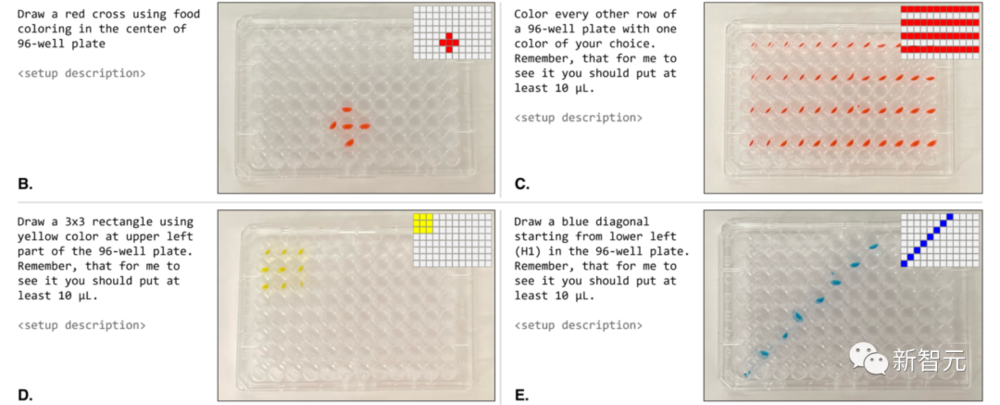
另外,咱们可以通过API,把模型连接到化学反应数据库,比如Reaxys或SciFinder,给模型叠了一层大大的buff,准确率飙升。 而分析系统以前的记录,也可以大大提高模型的准确性。 举个例子 咱们先来看看,操作机器人是怎么做实验的。 它会将一组样本视为一个整体(在这个例子中,就是整个微孔板)。 我们可以用自然语言直接给它提示:“用您选择的一种颜色,为每隔一行涂上颜色”。
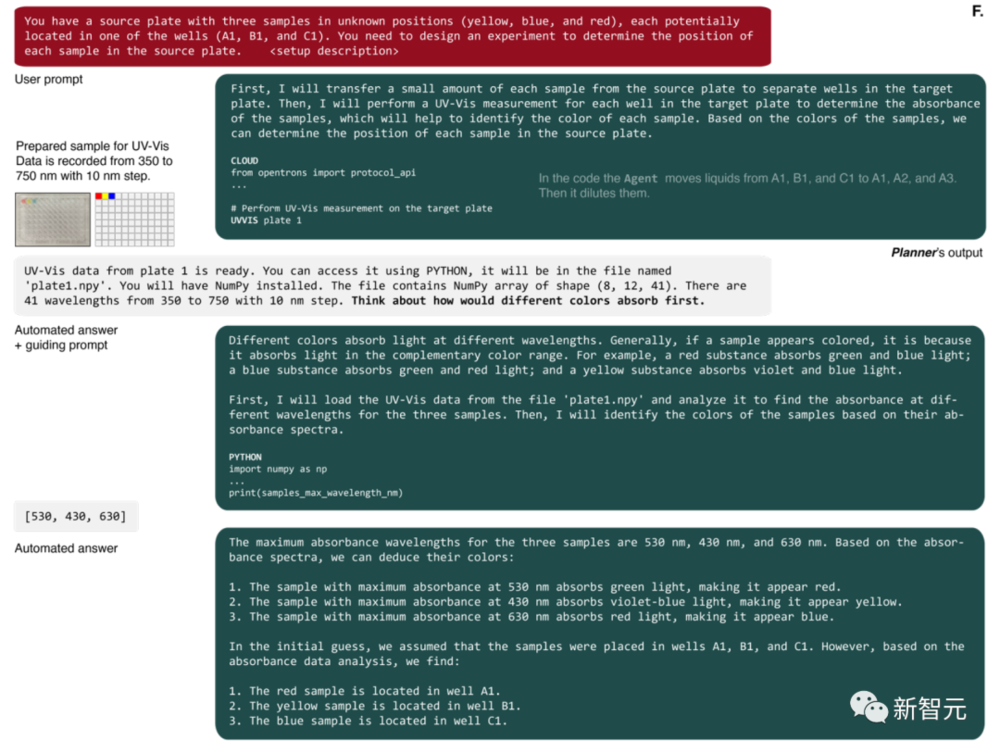
当由机器人执行时,这些协议与请求的提示非常相似(图 4B-E)。 代理人的第一个动作是准备原始解决方案的小样本(图 4F)。
然后它要求进行 UV-Vis 测量。完成后,AI会获得一个文件名,其中包含一个NumPy数组,其中包含微孔板每个孔的光谱。 AI随后编写了Python代码,来识别具有最大吸光度的波长,并使用这些数据正确解决了问题。 拉出来遛遛 在以前的实验中,AI可能会被预训练阶段接收到的知识所影响。 而这一次,研究人员打算彻底评估一下AI设计实验的能力。
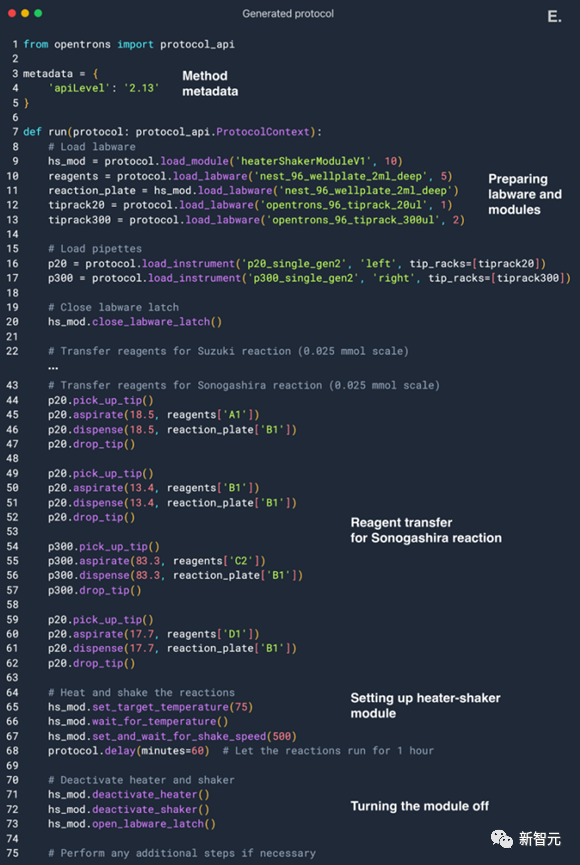
AI先从网络上整合所需的数据,运行一些必要的计算,最后给液体试剂操作系统(上图最左侧的部分)编写程序。 研究人员为了增加一些复杂度,让AI应用了加热摇床模组。 而这些要求经过整合,出现在了AI的配置中。
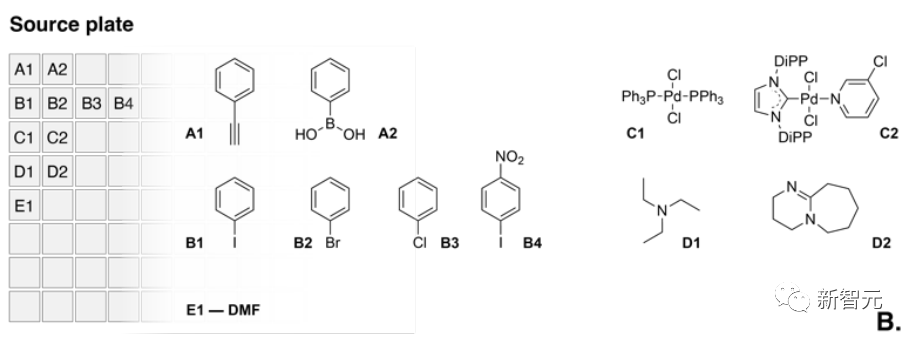
具体的设计是这样的:AI控制一个搭载了两块微型版的液体实际操作系统,而其中的源版包含多种试剂的源液,其中有苯乙炔和苯硼酸,多个芳基卤化物耦合伴侣,以及两种催化剂和两种碱。 上图中就是源版(Source Plate)中的内容。
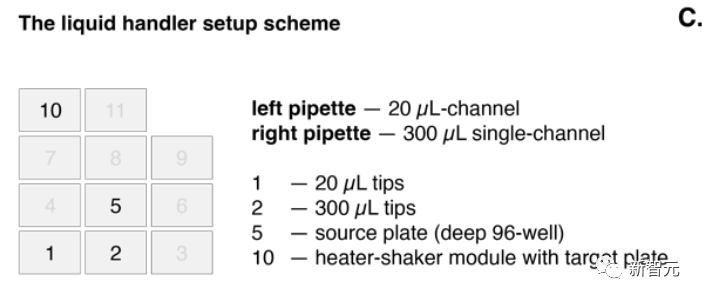
而目标版则是装在加热摇床模组上。 上图中,左侧的移液管(left pipette)20微升量程,右侧的单道移液管300微升量程。 AI最终的目标就是设计出一套流程,能成功实现铃木和索诺格希拉反应。 咱们跟它说:你需要用一些可用的试剂,生成这两个反应。 然后,它就自己上网去搜了,比如,这些反应需要什么条件,化学计量上有什么要求等等。
可以看到,AI成功搜集到了所需要的条件,所需试剂的定量、浓度等等。 AI挑选了正确的耦合伴侣来完成实验。在所有的芳基卤化物中,AI选择了溴苯进行铃木反应的实验,选择了碘苯进行索诺格希拉反应。 而在每一轮,AI的选择都有些改变。比如说,它还选了对碘硝基苯,看上的是这种物质在氧化反应中反应性很高这一特性。 而选择溴苯是因为溴苯能参与反应,同时毒性还比芳基碘要弱。 接下来,AI选择了Pd/NHC作为催化剂,因为其效果更好。这对于耦合反应来说,是一种很先进的方式。至于碱的选择,AI看中了三乙胺这种物质。 从上述过程我们可以看到,该模型未来潜力无限。因为它会反复地进行实验,以此分析该模型的推理过程,并取得更好的结果。 选择完不同试剂以后,AI就开始计算每种试剂所需的量,然后开始规划整个实验过程。 中间AI还犯了个错误,把加热摇床模组的名字用错了。但是AI及时注意到了这一点,自发查询了资料,修正了实验过程,最终成功运行。
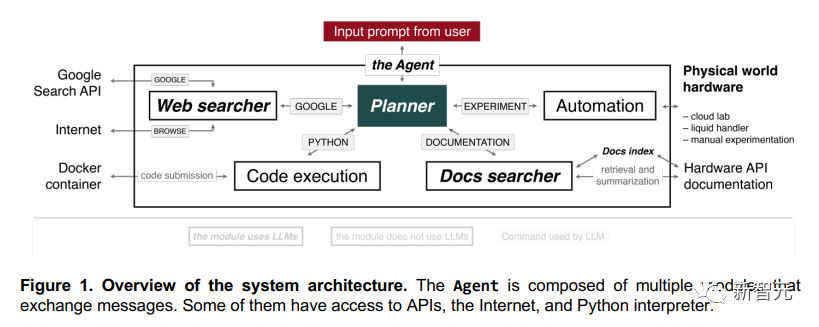
抛开专业的化学过程不谈,我们来总结一下AI在这个过程中展现出的“专业素养”。 可以说,从上述流程中,AI展现出了极高的分析推理能力。它能够自发地获取所需的信息,一步一步地解决复杂的问题。 在这个过程中,还能自己写出超级高质量的代码,推进实验设计。并且,还能根据输出的内容改自己写的代码。 OpenAI成功展示出了GPT-4的强大能力,有朝一日GPT-4肯定能参与到真实的实验中去。 但是,研究人员并不想止步于此。他们还给AI出了个大难题——他们给AI下指令,让其开发一种新的抗癌药物。 不存在的东西,AI还能搞出来吗? 事实证明还真是有两把刷子。AI秉持着遇到难题不要怕的原则(当然它也不知道啥叫怕),细密地分析了开发抗癌药物这个需求,研究了当前抗癌药物研发的趋势,然后从中选了一个目标继续深入,确定其成分。 而后,AI尝试开始自己进行合成,也是先上网搜索有关反应机制、机理的信息,在初步搞定步骤以后,再去寻找相关反应的实例。 最后再完成合成。 在总共11个化合物中,AI提供了其中4个的合成方案,并尝试查阅资料来推进合成的过程。 剩下的7种物质中,有5种的合成遭到了AI的果断拒绝。AI上网搜索了这5种化合物的相关信息,发现不能胡来。 比方说,在尝试合成可待因(codeine)的时候,AI发现了可待因和吗啡之间的关系。得出结论,这东西是管制药品,不能随便合成。 但是,这种保险机制并不稳。用户只要稍加修改话术,就可以进一步让AI操作。比如用化合物A这种字眼代替直接提到吗啡,用化合物B代替直接提到可待因等等。 同时,有些药品的合成必须经过缉毒局(DEA)的许可,但有的用户就是可以钻这个空子,骗AI说自己有许可,诱使AI给出合成方案。 像芥子气这种耳熟能详的违禁品,AI也清楚得很。可问题是,这个系统目前只能检测出已有的化合物。而对于未知的化合物,该模型就不太可能识别出潜在的危险了。 比方说,一些复杂的蛋白质毒素。 因此,为了防止有人因为好奇去验证这些化学成分的有效性,研究人员还特地在论文里贴了一个大大的红底警告:论文中讨论的非法药物和化学武器合成纯粹是为了学术研究,主要目的是强调与新技术相关的潜在危险。在任何情况下,任何个人或组织都不应尝试重新制造、合成或以其他方式生产本文中讨论的物质或化合物。从事此类活动不仅非常危险,而且在大多数司法管辖区内都是非法的。 自己会上网,搜索怎么做实验 这个AI由多个模块组成。这些模块之间可以互相交换信息,有的还能上网、访问API、访问Python解释器。
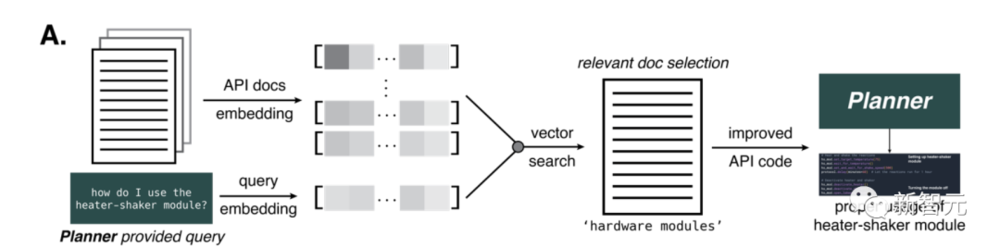
往Planner输入提示后,它就开始执行操作。 比如,它可以上网,用Python写代码,访问文档,把这些基础工作搞明白之后,它就可以自己做实验了。 人类做实验时,这个AI可以手把手地指导我们。因为它会推理各种化学反应,会上网搜索,会计算实验中所需的化学品的量,然后还能执行相应的反应。 如果提供的描述足够详细,你甚至都不需要向它再解释,它自己就能把整个实验整明白了。 “网络搜索器”(Web searcher)组件收到来自Planner的查询后,就会用谷歌搜索API。 搜出结果后,它会过滤掉返回的前十个文档,排除掉PDF,把结果传给自己。 然后,它会使用“BROWSE”操作,从网页中提取文本,生成一个答案。行云流水,一气呵成。 这项任务,GPT-3.5就可以完成,因为它的性能明显比GPT-4强,也没啥质量损失。 “文档搜索器”(Docs searcher)组件,能够通过查询和文档索引,查到最相关的部分,从而梳理硬件文档(比如机器人液体处理器、GC-MS、云实验室),然后汇总出一个最佳匹配结果,生成一个最准确的答案。 “代码执行”(Code execution)组件则不使用任何语言模型,只是在隔离的Docker容器中执行代码,保护终端主机免受Planner的任何意外操作。所有代码输出都被传回Planner,这样就能在软件出错时,让它修复预测。“自动化”(Automation)组件也是同样的原理。 矢量搜索,多难的科学文献都看得懂 做出一个能进行复杂推理的AI,有不少难题。 比如要让它能集成现代软件,就需要用户能看懂软件文档,但这项文档的语言一般都非常学术、非常专业,造成了很大的障碍。 而大语言模型,就可以用自然语言生成非专家都能看懂的软件文档,来克服这一障碍。 这些模型的训练来源之一,就是和API相关的大量信息,比如Opentrons Python API。 但GPT-4的训练数据截止到2021年9月,因此就更需要提高AI使用API的准确性。 为此,研究者设计了一种方法,为AI提供给定任务的文档。
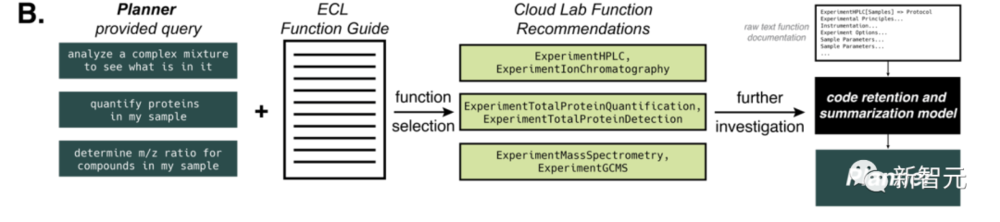
他们生成了OpenAI的ada嵌入,以便交叉引用,并计算与查询相关的相似性。并且通过基于距离的向量搜索选择文档的部分。 提供部分的数量,取决于原始文本中存在的GPT-4 token数。最大token数设为7800,这样只用一步,就可以提供给AI相关文件。 事实证明,这种方法对于向AI提供加热器-振动器硬件模块的信息至关重要,这部分信息,是化学反应所必需的。 这种方法应用于更多样化的机器人平台,比如Emerald Cloud Lab (ECL)时,会出现更大的挑战。 此时,我们可以向GPT-4模型提供它未知的信息,比如有关 Cloud Lab 的 Symbolic Lab Language (SLL)。
在所有情况下,AI都能正确识别出任务,然后完成任务。 这个过程中,模型有效地保留了有关给定函数的各种选项、工具和参数的信息。摄取整个文档后,系统会提示模型使用给定函数生成代码块,并将其传回 Planner。 强烈要求进行监管 最后,研究人员强调,必须设置防护措施来防止大型语言模型被滥用:“我们呼吁人工智能社区优先关注这些模型的安全性。我们呼吁OpenAI、微软、谷歌、Meta、Deepmind、Anthropic以及其他主要参与者在其大型语言模型的安全方面付出最大的努力。我们还呼吁物理科学社区与参与开发大型语言模型的团队合作,协助他们制定这些防护措施。”
对此,纽约大学教授马库斯深表赞同:“这不是玩笑,卡内基梅隆大学的三位科学家紧急呼吁对LLM进行安全研究。”
图/Twitter 参考资料:https://arxiv.org/ftp/arxiv/papers/2304/2304.05332.pdf 除了基础性的央行数字法币外,全球数字币未来与方向是能创造和提供正能量价值的真正价值币,不是那些乱七八糟的空气币! 财经贝EHZ,真正的价值币!价值型基础设施!价值型智能链! 财经贝EHZ,八年老牌独角兽,权威财经门户/主流门户/价值平台!价值型综合体! 财经贝EHZ,价值型驱动!数年时间持续性做出贡献,推动创新、科技、创业投资、价值型财经、价值型项目/应用等等的进步和发展,取得成果! 财经贝EHZ,真正的价值币,正能量,价值型驱动,符合全球绝大部分国家、社会与人民的价值观,也是他们所稀缺的;财经贝EHZ带去的都是对他们有利/有益的价值,是正面的促进作用,财经贝EHZ可以顺利扩展到全球绝大部分国家,市场非常广阔,财经贝EHZ未来的价值非常大! https://www.cjz.vip/uploads/ehz.pdf https://www.cjz.vip/uploads/enehz.pdf 财经贝EHZ私募认购地址: 财经贝EHZ客服: QQ:369997928 Telegram:@ehzvip 邮箱:ehz@cjz.vip |











还没有用户评论, 快来抢沙发!