


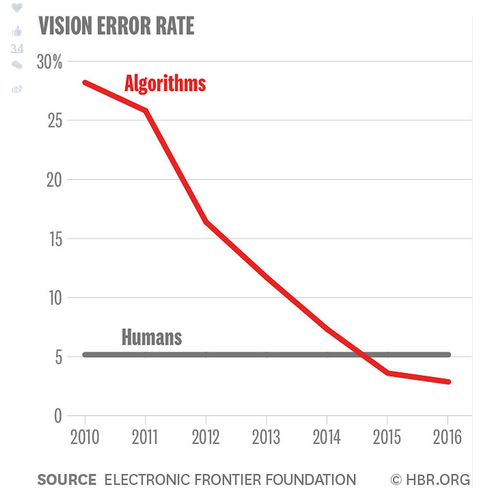
编者按:本文原作者是Erik Brynjolfsson和Andrew McAfee。Erik是麻省理工数字经济学专业负责人,麻省理工学院斯隆管理学院管理学教授以及NBER研究顾问。他的研究方向是信息技术对商业战略、生产效率和性能、数字经济和无形资产的影响。Andrew则是一名重要的麻省理工学院研究员,研究数字技术如何改变商业、经济和社会。 250多年来,技术创新是经济增长的根本动力。其中扮演最重要角色的是经济学家所说的通用技术,例如蒸汽机、电力和内燃机。每一次通用技术的兴起都推动了新一轮的创新浪潮。例如,内燃机促进了汽车、卡车、飞机等的出现,进而又催生了大型零售商、购物中心甚至新的供应链。而诸如沃尔玛、UPS和Uber这样的多样化公司又利用相关技术创造出了有利可图的新商业模式。 我们这个时代最重要的通用技术就是人工智能,特别是机器学习。所谓机器学习是机器无需人类的具体指令就可以不断提升其性能。在过去几年中,机器学习已经变得更加高效,并被广泛的使用。现在我们可以构建出能够自我学习如何执行任务的系统。 为什么这很重要?两个原因。首先,我们人类的认知水平是有限制的,很多事情是我们无法解释的,比如如何识别人脸或者如何决定在围棋对赛中的下一步。在机器学习之前,这种无法表达出自己认知的现象导致我们无法将许多任务的执行自动化。但是现在有了机器学习的帮助,我们可以做到这一点。 其次,机器学习系统往往是非常优秀的学习者。他们可以在大规模活动中获得惊人的表现,比如监测欺诈或者诊断疾病。机器学习系统正被广泛部署在整个经济体系中,其影响将是深刻的。 在商业领域,AI在早期通用技术的规模上有着革命性的影响。虽然它已经被世界各地数千家公司所使用,但是绝大多数潜能还尚未被挖掘出来。随着制造业、零售业、交通运输业、金融业、医疗保健业、法律业、广告业、保险业、娱乐业、教育业等各行业转变核心流程和商业模式,充分利用机器学习,AI效应将会在未来数十年内被放大。目前的瓶颈在于管理、实施和商业构想方面。 但是,像许多其他新技术一样,人工智能已经产生了许多不切实际的期望。我们可以看到很多商业计划都涉及了机器学习、神经网络等技术,但实际上却没有什么联系。例如,一个号称使用AI技术的约会网站并不会让约会过程更加高效,提出AI可能只是为了方便融资。本文将抛开不切实际的成分,来深究AI真正的潜力,探寻它的实际意义以及可能遇到的障碍。 如今要如何面对?人工智能一词是由达特茅斯大学数学教授John McCarthy在1955年创造出来的,他于次年组织了有关AI的学术性会议。从那以后,也许是因为这个吸引人的名字,AI领域已经被给予了太多的期望。1957年,经济学家Herbert Simon预测,计算机将在10年内在国际象棋比赛中击败人类。(实际上花费了40年。)1967年,认知科学家Marvin Minsky认为只需要一代人,创造人工智能的问题将会得到实质性的解决。虽然Simon和Minsky都是顶尖的科学家,但是他们对AI的认知却是错误的。所以当他们提出这种夸张的预测时,遇到了一定程度的质疑。 让我们先来看看AI目前所做的事情,以及提升的速度。目前AI在两个方面获得了巨大突破:感知和认知。感知方面,已经有一些实际性的进展。虽然语音识别还远远算不上完美,但是现在已经有上百万人正在使用,例如Siri、Alexa和谷歌助手。现在你所看到的文字就是通过语音录入计算机,并以一定的精度进行转录,从而比打字的速度更快。斯坦福大学计算机科学家James Landay及其同事进行的一项研究发现,语音识别平均要比手动输入快到3倍。而曾经8.5%的错误率也下降到了4.9%。更令人震惊的是,这一重大性能提升并不是从过去十年开始发生的,而是从2016年夏天开始的。 图像识别也得到了显着提升。你可能已经注意到,Facebook等应用现在可以从照片中识别出人脸,并会有提示你贴上人名标签。运行在智能手机上的应用几乎可以识别出所有的野生鸟类。图像识别甚至取代了一些公司总部的身份卡。过去,用于自动驾驶汽车的视觉系统在以30帧的频率识别行人时会频繁出现错误;而现在这一数字提升到了3000万,识别错误率也不断下降。用于识别图像的大型数据库ImageNet拥有数百万张各种常见与不常见的图片,它的错误率从2010年的30%以上降至2016年的4%。
由于采用了基于更多更深的神经网络方法,近年来性能提升速度正在加快。虽然视觉系统的机器学习方法仍然没有达到完美程度,但是它们却能比人类更精确的识别出图像的差别。 第二类重大突破主要在认知和问题解决上。现在机器已经战胜了最好的扑克玩家和围棋玩家,而此前专家们预计至少需要十年时间才能达到这一程度。谷歌的DeepMind团队使用机器学习系统将数据中心的冷却效率提升了15%,虽然机器学习系统仍然是由人类专家进行优化的。网络安全公司Deep Instinct正在使用智能代理来检测恶意软件,并通过PayPal防止洗钱。新加坡一家使用IBM技术的保险公司可以实现自动索赔,而数据科学平台公司Lumidatum的系统可以提供及时建议,改善客户支持。华尔街几十家公司正在使用机器学习来决定交易,越来越多的信贷决策都是在它们的帮助下完成的。亚马逊通过部署机器学习系统来优化库存,并改善向客户提供的产品建议。Infinite Analytics开发的机器学习系统可以预测用户是否点击特定广告,改善在线广告的展示位置,改善在线零售的客户搜索和发现流程。 机器学习系统不仅在许多应用中替代旧的算法,而且在人类曾经最擅长的任务中表现优越。虽然这些系统远未达到完美程度,但是它们的错误率只有约5%,性能高于人类。即使在嘈杂的环境中,语音识别也几乎达到了人类的水平。这也为工作和经济的转变提供了巨大的可能性。一旦AI系统在给定的任务中超越了人类的表现,它们就会很快占领这一领域。例如,无人机制造商Aptonomy和机器人制造商Sanbot正在合作使用改进的视觉系统将保安工作实现自动化。软件公司Affectiva正在使用AI系统来识别出对照组中的喜悦、惊讶和愤怒情绪。深度学习创企Enlitic利用AI系统扫描医学图像来帮助诊断癌症。 以上都是非常令人印象深刻的成就,但是这些AI系统的适用性仍然是狭义的。例如,它们在ImageNet数据库上的卓越表现,并不总是出现的,其中照明条件、角度、图像分辨率等都会导致结果的不同。更简单的一个例子是,它们可以将一篇中文文章翻译成英文,但是却不知道具体汉字的意思。如果有人出色的完成了一项任务,我们一般会认为这个人也可以出色的完成类似任务。但是机器学习系统往往是被训练完成特定的任务,所以它们的知识并不具有一般性。对于计算机狭义理解必然包含广义理解的这一谬误可能是人工智能发展过程中最不切实际的说法。现在的机器还远未达到能够跨领域执行任务的程度。 理解机器学习关于机器学习有一点是最重要的:机器学习代表了一种完全不同的软件创建方法。机器从示例中自我学习,而不是针对特定结果进行明确的编程。这也是在以往做法上的重大突破。在过去50年的大部分时间里,信息技术及其应用的进步都是编码现有的知识和程度,并将之嵌入到机器中。实际上,“编码”这个术语就是表示将开发人员大脑中的知识转变成机器能够理解和执行的形式的过程。这种方法有一个根本的弱点:大多数知识都是默认的,我们无法完全解释它。我们几乎不可能编写出如何让一个人学习骑自行车或者识别人脸的程序。 换句话说,很多事情是我们无法描述的。这个事实是非常重要的,它被称为波拉尼悖论(Polanyi's Paradox)。哲学家和博学者Michael Polanyi在1964年的时候提出了这一悖论。波拉尼悖论不仅限制了我们对事情的描述,也限制了我们赋予机器智能的能力。很长一段时间,波拉尼悖论也限制了机器在经济中更有效地发挥作用。 但是机器学习克服了这些限制。在第二次机器时代的第二次浪潮中,人类所构建的机器正在从示例中自我学习,并使用结构化的反馈来解决问题。 机器学习的不同之处人工智能和机器学习有很多相同的地方,但是近年来大多数成功的例子都是在监督学习系统。在这一系统中机器被给予了许多特定问题正确答案的例子。这个过程几乎就是从一组输入X到一组输出Y的映射。例如,输入可能是各种动物的图片,正确的输出可能是这些动物的标签:狗、猫、马。输入也可以是声音波形,输出可以是“是”、“不”、“你好”、“再见”。 成功的系统通常会使用拥有数千甚至数百万个示例的训练集,其中每一个示例都被标记上了正确答案。系统还会不断的加入新例子。如果训练能够顺利进行,那么系统的预测将会具有高准确率。 驱动这种成功的算法依赖于一种被称为深度学习、使用神经网络的方法。深度学习算法比早期的机器学习算法具有显著的优势:它们可以更好地利用更大的数据集。随着训练集中示例数量的增加,旧系统的性能将会得到提升,但是这一提升是有限度的,因为新加入的数据并不会导致更好的预测结果。AI领域的巨头吴恩达认为,深度神经网络不应该是这样的结果,更多的数据应该会得到更好的预测。有一些大型系统会使用3600万甚至更多个示例进行训练。当然,使用极大的数据集则需要更强大的处理能力,这也是大型系统为什么会运行在超级计算机或专用计算机体系结构上。 通过大量行为数据预测数据就是监督学习系统的潜在应用。主管亚马逊消费者业务的Jeff Wilke认为,监督学习系统已经在很大程度上取代了基于记忆的滤波算法。在其他情况下,用于设置库存水平和优化供应链的经典算法已被基于机器学习的更有效和更稳定的系统所替代。摩根大通引进了用于审核商业贷款的系统,以往需要贷款审核人员花费36万小时完成的任务只需要短短几秒钟就可以完成了。此外,监督学习系统也被用于诊断皮肤癌。 标示一组数据并用它来训练监督学习系统是比较简单的,这就是为什么监督学习系统要比无监督学习系统更加常见。而无监督的学习系统则依赖于自我学习。我们人类就是优秀的无监督学习者。我们所接收的大部分知识都是没有标示的数据。但是要想开发出成功的无监督机器学习系统却是非常困难的。 如果我们可以打造出稳定的无监督学习系统,那就会开启无数的可能性。这些机器可以以全新的方式来看待复杂的问题,帮助我们找到人类不了解的事物内部模式。 该领域另一个虽小但不断增长的部分是强化学习。这种方法被嵌入到了Atari游戏视频和围棋比赛中。它也有助于优化数据中心的电力使用,并为股市制定交易策略。Kindred创造的机器人使用机器学习来识别和排序他们未曾见过的物品,并加快消费品配送中心的分拣过程。在强化学习系统中,程序员指定系统的当前状态和目标,列出可允许的操作,并描述限制每个动作结果的环境要素。通过使用经过允许的操作,系统可以找到最接近目标的方式。这些系统也可以处理人类能够指定目标但不一定需要亲自操作的任务。例如,微软使用强化学习来选择MSN.com新闻报道的标题,当链接被更多的访问者点击时,会给予系统一个更高的分数。系统会在设计师给予的规则的基础上尽可能的最大化分数。当然,这也意味着强化学习系统会以你明确奖励的目标为优先,而不一定是你真正关心的目标(比如客户终身价值),所以正确且清楚的制定目标是至关重要的。 将机器学习应用于工作对于希望使用机器学习的公司来说,这里有三个好消息。第一,AI技术正在迅速普及。目前数据科学家和机器学习专家是非常稀缺的,但是网络教育资源和大学教育正在填补这一需求。其中最好的在线培训(比如优达学城、Coursera和fast.ai)不仅仅在教授入门概念,他们也在让聪明积极的学生达到能够创造工业级机器学习部署的水平。除了培养自己的员工,一些对AI感兴趣的公司正在使用诸如Upwork、Topcoder和Kaggle等在线技能平台寻找具有专业技能的机器学习专家。 第二,现在可以根据需要购买或租赁必要的算法和硬件。谷歌、亚马逊、微软、Salesforce等公司正在通过云架构建立强大的机器学习框架。这些竞争对手之间的竞争将会创造出更多更好更强大的机器学习功能,让众多想要部署机器学习系统的中小公司受益。 最后一个好消息是,你可能不需要所有的数据就可以高效的利用机器学习。由于大多数机器学习系统都经过了大量数据的训练,其性能有了很大的提升。当然,这也意味着拥有最多数据的公司将会成为最后的赢家。这里的“赢”是指在单一应用的全球市场占据主导地位。但如果是指拥有显著提升的性能,那么只需要有足够的数据就可以很容易的实现这一目标。 例如,Udacity的联合创始人Sebastian Thrun表示,他的一些销售人员在回复聊天时要比其他人更加高效。Thrun和他的研究生Zayd Enam意识到,他们的聊天日志本质是就是一组被标示的训练数据,完全就是监督学习系统所需要的。有互动的被标示为成功,其他的则标示为失败。Zayd使用这些数据来预测成功的销售人员可能会对某些非常常见的查询做出响应,然后与其他销售人员分享这些预测,以推动他们更好的表现。经过1000个训练周期,销售人员的效率提高了54%,一次可以服务两倍的客户。 AI创企WorkFusion也是采用了类似方法。它与众多公司进行合作,提升了诸如国际支票支付和金融机构大型交易处理等后台流程的自动化水平。这些流程尚未自动化的原因是很复杂的,因为相关信息并不总是以相同的方式呈现,有些解释和判断是必要的。WorkFusion的软件可以在后台匹配从业人员的工作,使用他们的操作行为作为分类认知操作的训练数据。一旦系统对分类过程具备足够的信心,它将接管整个过程。 机器学习正在推动三个层面的变革:职业,业务流程和商业模式。以职业为例,通过使用机器视觉系统来识别潜在的癌症细胞,可以将放射医师解放出来,让他们专注于真正关键的病例,专注于和病人的交流,专注于和其他医师的协调。业务流程方面,亚马逊通过引入基于机器学习的机器人和优化算法,对物流中心的工作流和布局进行了改造。商业模式方面,则是利用机器学习个性化智能推荐音乐或电影。不再以消费者选择为基础销售单曲,而是提供根据预测个性化用户播放列表的订阅服务进行销售。 请注意,机器学习系统并不能替代完整的工作、流程和商业模式。大多数情况下,它们是作为人类活动的补充,让我们的工作更有价值。新形势下最有效的分工规则并不是“把任务都丢给机器完成。”而是让机器去处理可以自动化完成的步骤,剩下的具有价值的部分由人类来完成。例如,优达学城的聊天销售支持系统并不是接管所有对话的机器人,相反,该系统会给销售人员提出建议如何提高效益。整个系统仍然由人类来负责,但是会变的更加高效。这种方法通常也比包揽一切的机器更为可行。它可以给参与者带来更好更满意的工作,并最终给客户带来更好的结果。 设计和实施结合了技术、人类技能和资本的系统需要经历大量的创意思考和计划。而这是机器所不擅长的地方。 风险和局限第二次机器时代的第二次浪潮带来了新的风险。特别是机器学习系统通常具有很低的“可解读性”,这意味着人们难以确定系统是如何完成决定的。深度神经网络可能拥有数亿个连接,每一个连接都参与了最终的决策。因此,这些系统的预测往往无法用简单明了的语言进行解释。不像人类,机器并不能很好的讲述故事。他们无法给出接受或拒绝申请人的理由,无法给出推荐某种药物的理由。具有讽刺意味的是,即使我们已经开始克服波拉尼悖论,但是我们面临着一个逆向版本,即机器知道的比它能描述的多。 这造成了三种风险。第一,机器可能具有隐藏的偏差,这不是来自于设计师的意图,而是来自于用于训练系统的数据。例如,如果一个系统可以通过使用过去人力资源员工做出的决策数据来学习接受哪些求职者进行面试,那么它可能会无意中形成对种族、性别等的偏见。此外,这些偏见虽然不会作为一个明确的规则出现,但是却会嵌入在数千个因素的微妙交互中。 第二个风险是,与基于明确逻辑规则的传统系统不同,神经网络系统处理的是统计事实而不是文字事实。这可能难以完全确定该系统可以在所有情况下都能正常处理,特别是在训练数据没有提供的情况下。缺乏可验证性会成为关键任务应用中的一个问题,比如核电厂控制,或者涉及生死攸关的时刻。 第三,当机器学习系统发生错误时,出错是几乎不可避免的,而诊断和找到具体出错位置是很困难的。得出解决方案的基础结构可能是难以想象的复杂,如果系统训练的条件发生了变化,那么解决方案则不是最优化的。 虽然所有这些风险都是真实存在的,但是我们想要的并不是完美的标准,而是最好的替代方案。毕竟,我们人类也是有偏见的,也会犯错,有时也无法解释某个决定是如何达成的。基于机器的系统的优点是,随着时间的推移,它们可以得到改进,并且在呈现相同的数据时会给出一致的答案。 这是否意味着人工智能和机器学习是没有限制的?感知和认知涵盖了很多领域。我们相信,在大多数灵越,AI将会很快达到超人的水平。那么AI和机器学习有什么是无法做到的呢? 我们有时会听到“人工智能无法很好地评估具有情感、狡猾的人类,它们是没有人性的。”我们不同意这一观点。像Affectiva那样已经处于或超过人类表现的机器学习系统,可以根据声音或面部表情来辨别人的情绪状态。而其他系统在面对世界上最优秀的扑克玩家时,也能在最复杂的德州扑克比赛中击败他们。准确的阅读一个人是一件很微妙的工作,但不是什么魔术。它需要感知和认知的协作,而这正是机器学习最擅长的领域。 毕加索认为计算机是无用的,因为他们只会给你答案。这套用到现在AI也很适合。实际上鉴于机器学习的惊人表现,它们是非常有用的。但是毕加索的想法给我们提供了另一个角度。计算是用来回答问题的工具,而不是提出问题的设备。 同样,被动评估某人的精神状态或士气与积极改变之间存在着巨大差异。机器学习系统非常擅长前者,但是在后者却仍然远远落后于我们。我们人类是一个具有深刻社会性的物种,非常擅长于利用同情、骄傲等来达到激励和启发的目的。2014年,TED大会和XPrize基金会宣布将会给予第一个登上TED舞台、并能赢得观众起立鼓掌的人工智能奖励。估计这个奖项很快就会被领走。 我们相信,在这个机器学习超级强大的新时代,人类面临着两个方面的问题:弄清楚下一步需要解决什么;说服很多人解决问题提出解决方案。 很快,思想和机器之间的分裂状态将会结束。仍然保守成见的公司将会发现自己落后于拥抱机器学习的竞争对手。 技术进步带动了商业世界的构造变化。与蒸汽时代和电器时代一样,那些不愿意接触新技术的人将会在新的技术潮流中落败下来。相反,那些持有开放思想的创新者将会看到过去的限制,提出创新的想法,并付诸实践。机器学习最大的遗产之一可能就是创造出新一代的商业领袖。 我们认为,人工智能,特别是机器学习,是我们这个时代最重要的通用技术。这些创新对企业和经济的影响不仅体现在它们的直接贡献中,还体现在引导创新的能力上。通过更好的视觉系统、语音识别、智能解决方案等,将会创造出全新的产品和流程。 一些专家想的更深。现任丰田研究所的负责人Gil Pratt将目前的AI技术潮流比作5亿年前的寒武纪大爆发,后者创造出了大量新的生命形式。在未来一段时间内,我们将看到大量新产品、服务、流程和组织形式的出现,也会看到大量事物的消失。
虽然很难预测哪些公司将在新的环境中占据主导地位,但是有一点是明确的:适应性最强的公司将会蓬勃发展。那些能够快速感知和抓住机会的组织将会在AI创造的世界中占据优势。所以成功的策略就是愿意尝试和学习。如果主管没有尝试过机器学习领域,那就说明他没有做好本职工作。在接下来的十年中,AI不会取代到管理人员,但是那些使用AI的管理人员将会淘汰掉那些没有使用AI的人。 |


还没有用户评论, 快来抢沙发!